
이 논문은 적은 양의 입력으로도 NeRF를 수행할 수 있는 방법을 제안하고 있다. 위 동영상은 4장의 입력만으로 NeRF를 돌린 결과인데, 4장의 이미지에서 저런 일반화된 뉴럴 렌더링 결과가 나왔다는 사실이 굉장히 놀라웠다.
Motivation
이 논문의 목적은 Entropy 개념을 이용하여 regularization을 시도하는 것이다. 다른 별도의 모듈을 추가하거나, 학습을 추가하는 등의 복잡한 기법을 추가한 것이 아닌 정보 이론 개념을 활용한 loss term 추가만으로 이를 가능하게 했다는 점이 핵심이며, 이 덕분에 다른 많은 NeRF 모듈에 해당 방법을 붙이기 쉽게 적용할 수 있다고 한다. 추가로 유사도가 높은 viewpoint에서의 학습이 문제가 되어(Overfitting) 이에 대해 information gain을 추가 제안하고 있다. 이 두 가지 term을 loss에 추가하면서 결과적으로 train 당시 보지 못한 view에 대해서도 noise가 줄어든 결과를 얻을 수 있었다.
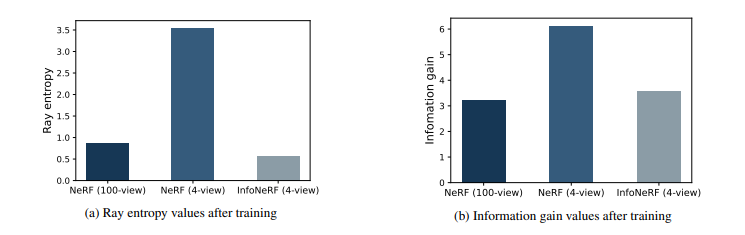
논문의 appendix에서는 이를 그래프로써 표현하며 부연설명을 하고 있다. NeRF에서, 처음에 100개의 view에 대한 이미지를 입력으로 넣었을 때는 상대적으로 많이 낮게 나왔던 density의 entropy나 information gain이 4개 view로 줄어들자 크게 높아진 것을 볼 수 있다. InfoNeRF에서는 이 두 부분을 loss term으로 추가함으로써 해당 값들을 최소화 해 여러 view에서 높은 정확도로 density를 추정하도록 한다.
Regularization by Ray Entropy Minimization
먼저 논문에서는 ray density를 normalize하여 확률처럼 접근할 수 있도록 바꾸었다.
$$ p(\textbf{r}_i) = \frac{\alpha_i}{\sum_j\alpha_j} = \frac{1-\exp(-\sigma_i\delta_i)}{\sum_j(1-\exp(-\sigma_j\delta_j))} $$
여기서 \(\alpha\)는 렌더링에서의 불투명도(opacity)를 의미한다. ray 내에 특정 sampled point의 density를 기반으로 이렇게 불투명도를 표현하고 있는데, 주로 이 표현은 volumetric rendering에서 많이 표현하는 부분이기도 하다. 수식을 해석하자면, 하나의 ray로부터 나온 모든 sampled point들의 density를 기준으로 하나의 sampled point를 normalize하고 있는 것이다. 이를 하나의 확률로써 간주하고, 이 각각의 sampled point의 density에 대한 entropy를 수식으로 표현하면 다음과 같다.
$$ H(\textbf{r}) = \sum^N_{i=1}p(\textbf{r}_i)\log{p(\textbf{r}_i)} $$
하나의 ray상에 있는 전체 density를 기준으로 entropy를 구하고 있는데, 이론 그대로 보자면 density 값이 일부 확실한 영역에만 높게 나왔다면 이 entropy 값은 낮을 것이고, 결과적으로 해당 영역에 확실하게 렌더링을 수행할 것이다. 반면, 여러 영역 여기저기에 density 값이 높다면 entropy 값은 크게 나올 것이다. 즉, 해당 ray에서의 렌더링을 진행하기 위한 확실성이 떨어짐을 의미하는 것이다. 결과적으로 이 부분에서는 entropy 값이 낮게 나오도록 유도하는 것이 핵심이다.
그러나 단순히 이 이론대로 진행하기에는 일부 ray에서 non-hitting case임에도 불구하고 low entropy가 나오도록 강요되는 경우가 있었다고 한다. 이러한 경우에는 잠재적인 artifact 생성의 문제를 야기하게 된다. 논문에서는 이러한 부분을 완화하기 위해 마스크를 적용해서 low density를 갖는 영역을 무시하고 진행하도록 한다.
$$ M(\textbf{r}) = \begin{cases}
1, & Q(\textbf{r}) > \epsilon \\
0, & otherwise
\end{cases}$$
여기서 Q는 하나의 ray에서 sample한 N개의 point에 대한 누적 불투명도를 의미한다. 이 누적 불투명도가 특정 임계치를 초과하면 유효한 영역으로, 그렇지 않을 경우에는 무시할 영역으로 간주한다. 이를 기반으로 최종적인 ray entropy loss를 정의하면 다음과 같다.
$$ L_{entropy} = \frac{1}{|R_s|+|R_u|}\sum_{\textbf{r}\in R_s\bigcup R_u}M(\textbf{r})\odot H(\textbf{r}) $$
특이한 점은 loss를 계산하기 위한 대상으로 trained image의 ray set과 unseen image의 ray set을 사용한다고 논문에서 설명한다. 이 부분이 이해가 되지 않았는데, trained image는 보통 학습 입력으로 넣는 이미지의 view를 생각하면 되고, unseen image는 그와는 다른 viewpoint에서 쏜 ray를 생각하면 된다고 한다. 보통 NeRF는 L2 Norm 기반의 rendering loss를 계산하기 때문에 이러한 unseen ray를 활용할 수 없는데, entropy loss는 별도의 ground truth를 요구하는 것이 아닌 불확실성을 낮추는 loss이기 때문에 이게 가능했다고 한다.
만약 모든 트레이닝 이미지가 유사한 뷰를 가지고 있다면, 모델 오버피팅이 발생할 것이며, 이는 unseen image에 대한 일반화를 어렵게 한다. 이에 본 논문에서는 Information gain을 기반으로 하여 이웃한 ray들 간 일관된 density distribution을 보장할 수 있는 추가 loss 제안한다. 주어진 기준 ray에 대해 viewpoint가 미묘하게 다른(논문에서는 5도 정도의 rotation 차이를 주고 있음) viewpoint를 선정하여 그 시점에서부터 ray를 sampling한다. Information Gain Loss는 이러한 두 ray 간의 normalized density를 KL-Divergence를 기반으로 둘 간의 차이 계산을 수행한다. 본 term의 목적은 둘 간의 차이를 최소화하는 것이다. 이 방법을 통해 논문에서는 인접한 viewpoint들끼리 일반화를 가능하게 했다고 주장한다.
$$ L_{KL} = \sum^N_{i=1}p(\textbf{r}_i)\log\frac{p(\textbf{r}_i)}{p(\tilde{\textbf{r}}_i)} $$
Overall Objective
$$ L_{Total} = L_{RGB} + \lambda_1L_{entropy} + \lambda_2L_{KL} $$
최종 loss function은 위 공식처럼 정의할 수 있다. 원래 NeRF에서 사용하던 Rendering loss에다가 entropy loss와 information gain loss를 일정 가중치를 주어서 계산한다. 여기서 rendering loss는 ground truth image를 기반으로 계산하는 supervised loss이며, 나머지 두 loss는 확률의 차이와 불확실성 자체를 낮추는 loss이기 때문에 unsupervised loss로 볼 수 있다.
Experimental results

위 표는 360도 synthetic data로부터 4개의 view를 샘플링하여 novel view synthesis를 수행한 결과를 나타낸다. 100개 view를 통해 novel view synthesis를 진행한 NeRF와 결과치를 비교하고 있는데, 4개 view로 렌더링을 한 NeRF뿐만 아니라 PixelNeRF나 DietNeRF와 비교했을때도 더 높은 수치의 정확도를 보여주고 있음을 알 수 있다.
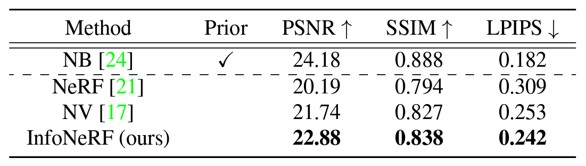

다음 실험은 추가로 Neural volumes(이하 NV) 논문과 Neural body(이하 NB) 논문, 그리고 NeRF를 비교군으로 하여 사람 객체에 대한 뉴럴 렌더링을 수행한 결과를 보여준다. 참고로 NB에 Prior가 들어가 있는데, 이는 Geometric prior가 사전에 들어가서 높은 정확도로 렌더링을 하기 위함이다. 이 실험의 목적은 geometric prior가 들어간 알고리즘과 비교했을 때, 4 view 기반 뉴럴 렌더링이 얼마나 잘 되는지를 비교하기 위한 실험으로 보이는데, NeRF나 NV에 비해서는 유실된 부분이 거의 없다시피하며 실제 ground truth의 외형을 잘 그려내려고 하는 것을 확인할 수 있었다.

좀 더 복잡한 scene에서의 뉴럴 렌더링 결과 또한 4 view에서도 잘 나오고 있었으며
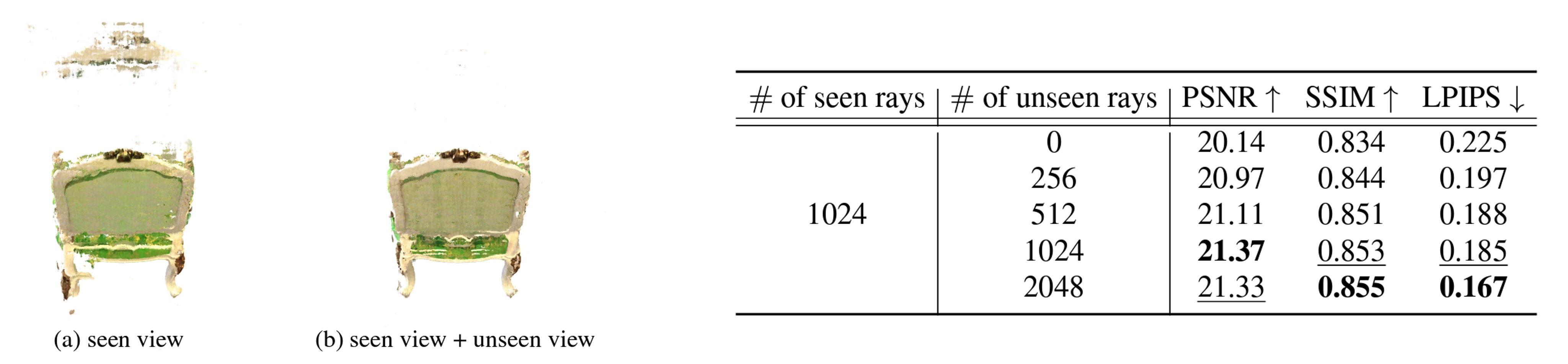
Unseen viewpoint 갯수가 렌더링에 미치는 영향을 보여주기 위해 unseen ray를 늘려가며 결과를 비교했다. 1024개 이상으로 unseen ray를 추가하니 그 이상 성능 향상이 보이지는 않았다. 수치상으로는 큰 변화가 있는 것 같지는 않으나, 그림 (a)와 (b)를 비교했을 때 artifact가 많이 줄어든 것을 확인할 수 있었다.

Entropy loss와 Information gain loss를 추가했을 때의 성능 변화는 위 실험 결과에서 확인할 수 있다. 특히, Entropy loss 유무에 따른 수치 차이가 더 벌어짐을 확인할 수 있었다.

해당 결과를 그림으로 나타내고 있는데, Information gain loss만 없는 경우보다 entropy loss만 없는 경우가 더 유실된 영역이 많았다. entropy loss가 없는 few-shot NeRF는 애초에 noisy reconstruction 결과가 나오기 때문에 이 상황에서 neighboring 간의 density 차이 최소화를 하는 information gain loss는 의미가 없기 때문이다.
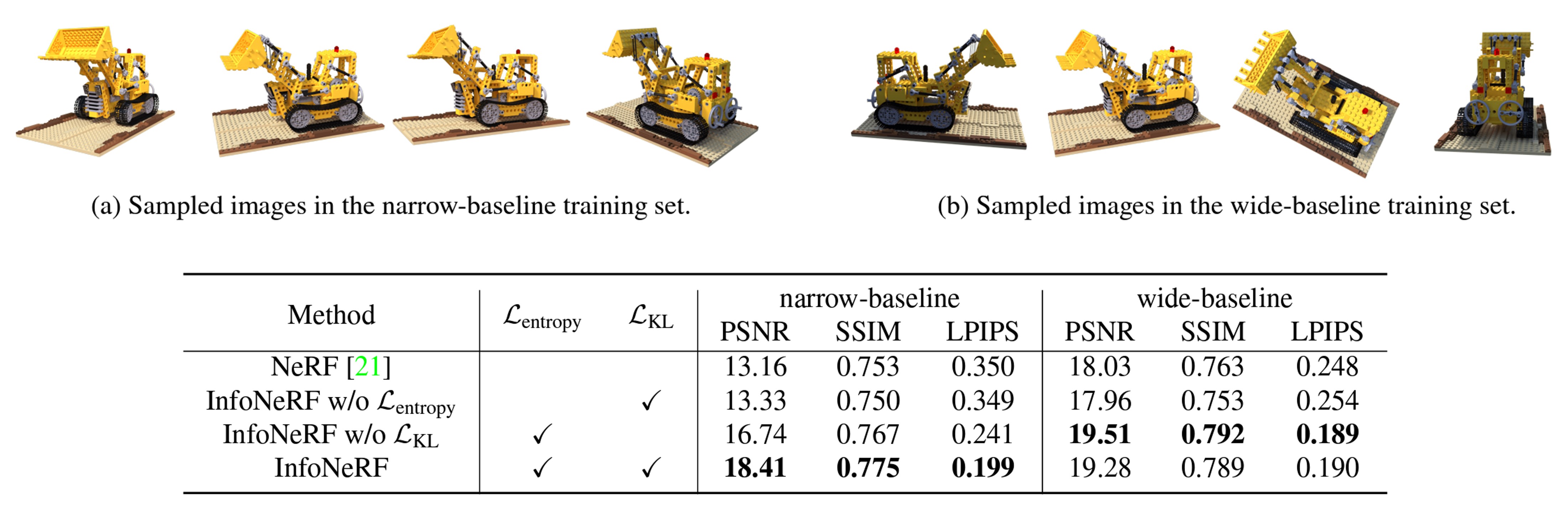
다음은 Information gain loss의 효과를 baseline에 따라 비교한 결과를 나타낸다. 위에서 말하는 narrow-baseline과 wide-baseline은 viewpoint 변화가 좁고 넓음의 차이에 대한 것을 나타낸다. Wide baseline에서는 Information gain loss가 있건 없건 큰 차이를 보이진 않았으나, narrow baseline에서는 성능 차이가 조금 더 크게 나는 것을 볼 수 있었다.

위 결과는 InfoNeRF를 PixelNeRF나 MipNeRF같은 다른 방법론에 함께 적용한 결과를 보여준다. InfoNeRF는 앞서 언급했듯이 다른 모듈이 추가된 것이 아니라 loss term만 추가되었기 때문에 다른 NeRF 알고리즘에 적용하기 좋다는 장점이 있다.

결과가 궁금해서 소스 코드를 직접 돌려봤는데, 이 렌더링 결과가 고작 4개의 view를 50,000번의 iteration만 돌려서 나온 결과라는 사실에 적잖이 놀랐다.
